
Sesión 7
Actividad 1
Existen 4 Platillos
- Ravioles
- Estofado
- Ensalada
- Pastel
- Los ravioles serán preparados por un hombre, sea Fernando o Diego.
- Ya que Fernando no cocinará el estofado por deducción tendrá que llevar los ravioles.
- Barrios es mujer y esta a dieta, solo comerá su platillo.
- Tina pidió vegetales en la ensalada, ello no llevara la ensalada, y como es la unica mujer que queda se deduce que sera el estofado.
- Pamela preparará la ensalada ya que esta a dieta y es lo único que comerá y Barrios es su apellido.
- Diego es el único hombre hasta el momento sin platillo por lo que por descarte el preparará el pastel.
- «Rodríguez preparará el pastel» Diego Rodríguez.
- Diego y Rios Hablan de la chica del estofado, hasta el momento sabemos que Pamela preparará la ensalada por lo que se queda fuera del cuadro, deduciendo que Fernando se apellida Rios.
- y Barrios platico con vargas así que Tina es Vargas.

Actividad 2



Sesión 8
Actividad 1

Índice
Contenido
Introducción.
Imaginemos un paciente en un hospital, recuperándose de una cirugía, y tiene conectado sensores para monitorear sus actividades biológicas en su cuerpo, como pueden serlo actividades cerebrales, ritmo cardiaco, niveles de estrés e incluso pulsaciones por minuto.
También imaginemos a un medico que trabaja para este hospital, el cual tiene la función de recibir esos datos, interpretarlos y llevar a cabo una serie de acciones para verificar la condición del paciente y su mejora; así mismo ahora cambiemos un poco el panorama y visualicemos a ese doctor como un trabajador del conjunto hospitalario, el cual debe cumplir con un horario de trabajo ya que debe registrar su entrada y salida en un lector biométrico digital, también tiene la obligación de llevar un expediente de los pacientes que ve en el día y vaciar la información de su condición de salud.
Estas y otras situaciones que pasan en la vida real tiene algo en común, y es que todas ellas generan datos una cantidad impresionable de datos por segundo y a esto lo llamaremos BIG DATA; entonces, quiero compartir con ustedes lectores que pertenecemos a una red increíblemente inmensa de fábrica de datos y que cada uno de nosotros tenemos una identidad en ella, algo así como una huella digital ya que todo lo que hacemos hoy en día queda registrado gracias a las tecnologías de la información.
Expuesto lo anterior ahora todos vemos de diferente manera la interacción que desempeñamos día a día en el hogar, trabajo, escuela o incluso en nuestros ratos de distracción.
La palabra BIG DATA es un termino que ha tenido moda en estos últimos años, y es utilizado en muchos temas de emprendimiento y tecnológicos a la cual le atribuyen la capacidad de impulsar cualquier negocio para producir millones de pesos.
Pero ciertamente esto es falso y fue lo que me orillo y motivo a realizar la siguiente investigación la cual he decidido en concluir con tres objetivos.
- Desmitificar los conceptos mal infundados del término BIG DATA
- Hacer conciencia de nuestro papel como generadores de datos
- Utilizar estos datos en un entorno altamente concurrido y de esta forma describir el comportamiento de una zona geográfica, además de desarrollar estrategias para mejorar el flujo de interacción precisando y facilitando la información de un individuo.
Metodología
Esta investigación fue realiza recabando información de libros, revistas, proyectos, tesis e incluso de entrevistas y ponencias videograbadas del tema central que es el BIG DATA.
Pero el mayor alcance que se tuvo con esta investigación que mostro varios panoramas y puntos para aterrizar el tema logrando una mayor compresión de la misma investigación con sus necesidades fue en la investigación de campo, la cual basa su estructura y contenido en una investigación mixta, centralizando su contenido en investigaciones posteriores y resaltando sus necesidades en herramientas de recolección de datos como encuestas y entrevistas, así como una profunda observación científica.
Para esta investigación fue necesario elegir una población, que concurriera un lugar y que el motivo de su visita no fuera tan variado de las demás muestras, así que la investigación de campo centro su estudió en un Conjunto Hospitalario el cual presta servicio a un área demográfica con una demanda superior a 30,000 personas en un lapso de 30 días promedio.
En esta investigación se catalogaron 3 muestras de las cuales su rol en el conjunto hospitalario relacionadas de la siguiente forma.
| Muestreo | Tipo | Lapso | Genera Datos | Candidato a Entrevista |
| Muestra 1 | Paciente | 1 a 2 Semanas | Si | Si |
| Muestra 2 | Médico | Indeterminado | Si | No |
| Muestra 3 | Trabajador | Indeterminado | Si | Si |
Ya que la investigación de campo fue muy corta y sirvió para resaltar las zonas en que se podría sacar provecho de esta investigación se decidió estructurarla de la siguiente manera.
- Profundizar en el termino BIG DATA, indagando su historia y analizando su comportamiento.
- Una vez formalizado y consolidado el termino BIG DATA el cual es punto de partida podremos desmitificar aquellas cualidades y atribuciones centrándonos en lo que realmente es.
- Llevar a la practica lo recabado de una forma teórica y no practica dejando al lector con una sensación que lo obligue a profundizar en materia.
¿Qué es el BIG DATA?
La palabra BIG DATA es un termino que se ha puesto de moda en estos últimos años, gracias a las personas dedicadas al marketing que toman un término y hacen modelos de negocios, promoción para impactar en innovación tecnológica y de esta forma promocionar sus servicios o levantar la imagen de la empresa, aunque en ocasiones realmente no se tenga conocimiento de cuando surgió sus funciones y lo que realmente es.
En la actualidad se piensa que la tecnología BIG DATA tiene la capacidad de impulsar cualquier negocio para producir ganancias exponenciales, pero realmente estas referencias son erradas y poco realistas del BIG DATA.
Pero entonces ¿Que es el BIG DATA?, para contestar esta pregunta veamos un ejemplo sencillo.
El teléfono celular es un gran invento que consolida diferentes herramientas tecnológicas en un solo aparato, en el, existe un reproductor de música y video, también tiene una agenda en la cual se pueden programar actividades con recordatorios, contiene conexión a internet de la cual podemos hacer consultas y navegar a sitios de interés así mismo encontramos un gestor de correo electrónico.
¿Pero cuál es el punto de esto?, para que este aparato pueda funcionar necesita un agente que interactúe con estas aplicaciones y que cada que lo haga poco a poco el dispositivo inteligente junto con las tecnología modernas reconozcan su actividad virtual, el tipo de música que escucha, sus pistas favoritas, el tipo de correo electrónico que envía y recibe el contenido que visualiza o frecuenta de la internet, las configuraciones de su equipo como puede ser la marca del celular, la resolución de la pantalla, las zona geográfica que frecuenta y es enviada por una aplicación de localización. Ahora ya no es necesario tener una cuenta y contraseña para que los sistemas nos identifiquen o reconozcan, somos portadores de una actividad virtual a la que podemos llamar huella digital y todo el tiempo que pasemos conectados a los aparatos inteligentes somos generadores de datos, información cada hora, minuto y segundo en cantidades inmensas que difícilmente podemos administra en bases de datos eso es el BIG DATA, la actividad que genera grandes volúmenes de datos.
Precedentes
En el momento en que surgieron las primeras formas de escritura almacenable en papiro hasta los centros de datos modernos, el hombre no ha dejado de recopilar la información que cree pudiera ser aprovechada para explicar o esclarecer incógnitas. En 1930 apareció hilado de historia que forma parte del BIG DATA, la sobre carga de información, el baby-boom en los Estados Unidos junto con la creación de números de seguridad social y el aumento de conocimiento e investigaciones fue suficiente para poner a trabajar a los expertos en un sistema de registro exhaustivo y mejor organizado.
Pero pese a estas medidas surgió un problema aun mayor ya que en el año de 1880, fue necesidad realizar una tabulación del censo que se llevo acabo en Estados Unidos y tardo cerca de ocho años en ser tabulado y el censo de 1890 tardo 10 años con los métodos y tecnologías disponibles en esa década.
Derivado de lo anterior la influencia de los datos generados entre 1880 y 1900 fue suficiente para que el ingenio de Hollerith inventara la maquina tabuladora, que funcionaba mediante tarjetas perforadas que a su vez fue capaz de domar esta gran cantidad de datos contenidos y realizar el trabajo en aproximadamente un año.
Con la invasión de la maquina tabuladora de Hollerith nace lo que actualmente conocemos como el gigante de innovación tecnología IBM.
El segundo reto al que se tuvo que enfrentar el hombre fue al almacenamiento y recuperación de datos, ya que se generaban exponencialmente por segundo, pero para su consulta o administración de forma precisa no se tenía la planificación ni formato de gestión de datos lo cual fue un problema aún más grande.
Podemos ejemplificar lo anterior mediante la visión de Fremont Rider, bibliotecario de la Universidad Wesleyana que calculó que las bibliotecas de las diferentes universidades de los Estados Unidos duplicaban su tamaño en un periodo frecuente de dieciséis años, calculando su tasa de crecimiento manteniéndose de esa forma la biblioteca de Yale tendría en el año 2040 aproximadamente cerca de doscientos millones de volúmenes, por lo que se necesitarían alrededor de seis mil personas para su gestión.
El crecimiento exponencial del conocimiento fue un gran paso para la humanidad pero supuso un problema de almacenamiento para lugares físicos como bibliotecas, centros hospitalarios y archivos de la nación así que con el crecimiento de la información en las décadas siguientes diversas organizaciones comenzaron el diseño e implementación de sistemas computados y centralizados de datos a lo cual estos sistemas fueron madurando en todas las diferentes industrias hasta llegar a su integración en diversas instituciones como sistemas de consulta, bibliotecas y censos nacionales.
El término Big Data fue empleado por primera en documentos de los investigadores de la NASA Michael Cox y David Ellsworth. “Ambos afirmaron que el ritmo de crecimiento de los datos empezaba a ser un problema para los sistemas informáticos actuales.
Mediante este proyecto de investigación, se le ha dado una cara al termino BIG DATA y se ha podido definir su empleabilidad, aunque es una herramienta útil para organizaciones o empresas que buscan almacenar, gestionar e interpretar los datos que generan, se requiere una preparación profesional que va desde crear un ambiente controlado, dar formato a los datos que se recopilaran hasta discriminar todo aquel dato que no cumpla con la regla de las tres v´s, velocidad de creación de datos, veracidad de los datos, dispersión y diversidad de los datos.
Dejo un diagrama que explica el concepto de las tres v´s.

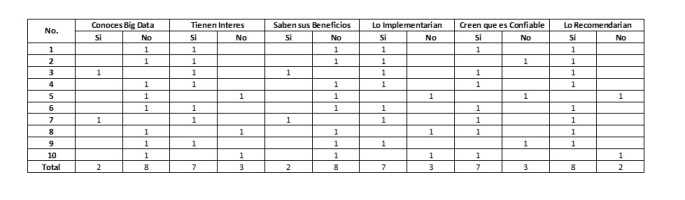
En la investigación de campo que se realizó en un centro hospitalario se pudo observar que las muestras mas frecuentes fueron, pacientes y doctores del conjunto hospitalario,
Los datos que ambas muestras generaban a pesar de ser grandes, veraces y variables así como frecuentes carecían de formato, organización y control, mostrando un centro hospitalario rudimentario y atrasado en tecnología, con tiempo desperdiciado y tiempos no optimizados, se concluye que aplicar el proyecto de forma practica seria viable por las características que se observan, así mismo se entrevisto a 10 candidatos de los cuales la mayor parte fueron doctores y que juegan un papel como trabajador, mientras ellos se interesaban por la explicación del termino Big Data y su empleabilidad para organizaciones como a la que ellos son parte, la otra parte de entrevistas mostro muy bajo interés en el tema.
Se concluye que la herramienta BIG DATA, es aplicable a conjuntos que manejan un sistema rudimentario de recopilación de datos.
A continuación, se anexan ejemplos de la entrevista que ser realizo y la gráfica de esta.
Referencias y fuentes de consulta
Referencias (formato APA)
- Historia Big Data
- (Contreras C, Open Data en México, 2017, pág. 54)
- (https://www.winshuttle.es/big-data-historia-cronologica/, 2018, pág. 1)
- (Pérez F., BIG DATA, s/f, pág. 16)
- ¿Qué es? Big Data
- (Baez M, Big data y analítica del aprendizaje en aplicaciones de, 2017, pág. 6)
- es, Disponible en: http://www.computerworld.es/sociedad-de-la-informacion/el-mercado-del-big-data-crecera-hasta-los-32400-millones-de-dolares-en-2017, 2013.
- (Camargo J, Camargo-Ortega J Y oyanes-Aguilar, Conociendo Big Data, 2014, pág. 77)
- Composición Big Data
- (Camargo J, Arquitectura tecnológica para Big Data, 2015)
- (ANÁLISIS COMPARATIVO DE LAS HERRAMIENTAS DE BIG DATA EN LA FACULTAD DE INGENIERÌA DE LA PONTIFICIA UNIVERSIDAD CATÓLICA DEL ECUADOR, 2017, pág. 114)
- Funcionalidad Big Data
- (Big Data, 2013, pág. 156)
- (Análisis de la estrategia Big Data en España, 2017, pág. 23)
- (Camargo J, Camargo-Ortega Joyanes-Aguilar, Conociendo Big Data, 2014, pág. 77)
- (Análisis de las posibilidades de uso de Big Data en las organizaciones, 2013 )
- Bárbara Madriaga. (2013). “El Big Data revolucionará la seguridad de la información”. CSO ESPAÑA
- Víctor Mayer-Schönberger Kenneth Cukier. (2013). “Big Data: La revolución de los datos masivos”, Universidad de Oxford
- Herramientas Big Data
- Michael Schroeck, Rebecca Shockley, Dra. Janet Smart, Dolores Romero-Morales, Peter Tufano. (2012). “Analíticos: el uso de Big Data en el mundo real”, IBM Institute for Business
- Implementación Big Data
- Michael Schroeck, Rebecca Shockley, Dra. Janet Smart, Dolores Romero-Morales, Peter Tufano. (2012). “Analytics: el uso de Big Data en el mundo real”, IBM Institute for Business
- Raúl G. Beneyto (2013). “Cuanta información se genera en el mundo “
“Big Data en Educación: El problema de la privacidad”, TIC, TAC, TEP: Aprender en el siglo XXI, 2015, [en línea]:https://palomarecuero.wordpress.com/2015/06/01/big-data-en-educacion-el-problema-de-la-privacidad/.
Sesión 8
Actividad 2









